
The Power of Prediction: Prologue's Data-Driven Approach to TA Orchestration

Patrick
CEO and co-founder of Prologue.
06/06/2023
In this post, we're taking a closer look at how we quantify pipeline health at Prologue. Though some parts delve into technical details, we've strived to keep the discussion accessible for all readers. Feel free to share your feedback in the comments below or reach out to us directly through our website at https://prologue.app.
Introduction
Prologue was developed with a singular aim: to enable our customers to hire in a candidate-first way. You can delve deeper into candidate-first on our website here, but to put it briefly:
Candidate-first hiring is a recruitment strategy that prioritizes the needs, experiences, and perspective of candidates throughout the hiring process. It aims to attract and secure top talent by aligning the company's mission, culture, and opportunities with the unique motivations and aspirations of potential employees.
For TA leaders, transitioning to candidate-first hiring is no small feat. It demands significant investment into developing an organisational structure (and culture) for delivering transparent, candidate-led, and engaging hiring experiences. Frequently this is done with limited bandwidth and tight schedules. Given this, it’s absolutely critical to allocate existing resources where they can make the biggest impact.
Role fill probability
The one resourcing question that TA leaders grapple with most is this: ‘What's the state of our ongoing roles and which require my attention?’ To gauge this, they typically rely on metrics like the number of candidates at each stage and pass-through rates; surfaced either by their ATS, or painstakingly assembled in Excel spreadsheets or BI tools.
These approaches carry several limitations. Firstly, collating these metrics across a large set of roles is more complex than it sounds - for instance, how does one build a unified measure of progress across roles that have different numbers and types of stages? Secondly, manually compiling these data points in Excel or a BI tool can be labor-intensive and prone to errors. Finally, sharing and presenting this data in an easily digestible (up-to-date) format isn’t easy or often even possible.
What TA leaders truly need - and what current metrics only approximate - is an answer to this: ‘Given our present candidate pool, what's the probability of filling each role?’. We believe that informed by this measure they will be able to focus their time on where it is truly needed most. That's exactly the reason we've incorporated a continually updated estimation of the likelihood of filling every open role into Prologue. In addition to this, we provide an explanation generated by GPT, outlining the rationale behind our quantitative assessment.
The Algorithm in 3 parts
We have developed our algorithm in a three-tier progression.
Version 1: The basic approach

In the most basic approach, we break each role down into its separate stages, assuming a certain percentage of candidates will progress from one stage to the next. This allows us to estimate how many of the current pipeline candidates we will likely extend offers to.logImage

In the above example, if we assume we have around 107 applicants, 7 in phone screen and 2 in interview, we will end up with approximately 1.3 + 0.9 + 0.5 = 2.7 candidates in offer. If we further assume some fixed acceptance rate like 50% we can work out that we have a 1 - 0.5 ^ 2.7 = 85% chance of this role being filled given our current pipeline of candidates.
This method applies universally to all roles, regardless of the number or nature of stages involved. As a bonus, it can be computed instantly.
Version 2: Incorporating drop-off.
The above approach works quite well but needs to be extended further before we can implement our full model. The idea here is that stage ‘progression’ is actually made up of two distinct processes - the company promoting candidates to the subsequent stage, and candidates leaving the process (for example losing interest, or accepting another offer).

We can determine the overall probability of a candidate moving from one stage to next by multiplying the two process probabilities together. So instead of a progression rate of 10% from application to screen now it is 0.1 * 0.8 = 0.08 8%. Once we’ve made this adjustment we can calculatue the overall job-fill probability using the method above.
Version 3: The full model
While the earlier models have their merits, they are built on static assumptions about each candidate's chances of moving forward at each stage. There are two areas where we can make improvements.
Firstly, by looking at the past data we've gathered on how candidates have moved through stages in Prologue, we can empirically deduce stage progression rates.
Secondly, we can tweak our model to take into account unique details of each candidate's situation. For example, how they've done in previous stages could hint at their likelihood of advancing in the current one, or their level of engagment might hint at the liklihood they will accept our offer. To put this into practice, we use a straightforward logistic regression. While it may not be as glamorous as some advanced Machine Learning methods, it's perfectly suited to give us realistic estimates of how candidates will, on average, progress.

One of the benefits of applying a logistic regression is it can be easily be fine-tuned for each Prologue customer, taking into account their unique evaluation methodologies (that we can directly learn from their historic data) and even the distinctive patterns of specific evalogImageluators or stages.
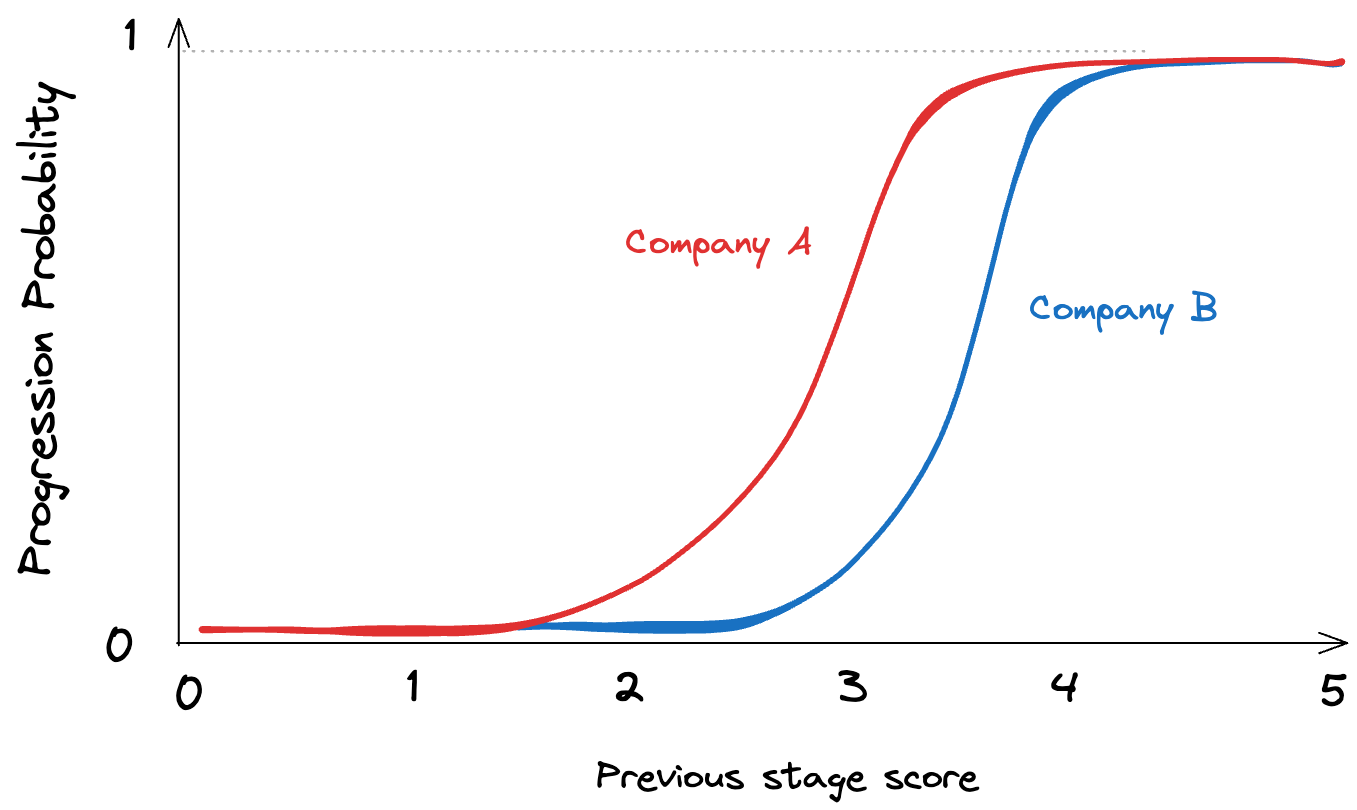
Some features of this approach
A model for every individual candidate
Our approach gives us a valuable side benefit: an educated guess on how likely each candidate is to move forward in the process. This serves two main purposes. First, it lets us use this information to enhance other features in our software — for instance, we could set up a Slack alert for a second look when a promising candidate is marked for disqualification. Second, it helps us anticipate what's ahead, like figuring out how many interviews we might need to conduct in the coming week. We're cautious about where we show individual probabilities in the product to prevent unintentional bias, but used wisely, this information is incredibly useful.
A GPT-interpretable output
We've experimented with leveraging GPT for providing more intelligent insights to our customers. While we've seen some success, it's clear that there are sizeable challenges in doing this in practice. Creating a completely customized model for each customer isn't feasible or consistently reliable, and inputting raw data into a single prompt doesn't work with the volume of data typically available in a recruitment process.
However, when we channel the outputs of our model into GPT, we see promising results. If we feed in the workings of our analysis It can accurately and consistently decipher the outputs and offer a succinct status update for a job role. This can be a straightforward statement like 'The role lacks sourced candidates' or a more sophisticated analysis like 'The two candidates at the offer stage are likely to decline and we have no backup'. Used in conjunction with the quantitative analysis this can be a useful starting point for interpretation.
A natural framework for recommendations
Given we have modelled how various aspects of your hiring process influence your candidates, we can also predict the potential impact of making changes to it. Whether it's modifying stages, switching reviewers, or other alterations, we can provide insights into the potential outcomes. While this is an area that warrants further exploration, we are well-equipped with the foundational tools to tackle it.
Next steps
We're currently looking into two promising avenues to enhance our role fill probability features. We'll give a quick overview now, and look forward to sharing them in a future blog post once they've been incorporated into the product.
Adding temporality
If 'Will this role be filled?' is the number one query from TA leaders, 'When will it happen?' definitely comes in a close second. In order to tackle the timing prediction, we'll need to expand our existing model. Currently, it's designed to calculate the likelihood of a candidate moving forward at each stage, but pinpointing exactly when this will occur presents a greater challenge. However, it's by no means an impossible task. The typical methodology to achieve this is known as 'survival analysis' and we're already testing its potential for predicting stage durations. With this in our toolkit, we anticipate being able to provide estimated fill dates along with their corresponding confidence intervals.
Monte Carlo simulation
One limitation of our present model is that it considers the progression of each candidate in isolation. This assumption holds when you're filling multiple vacancies for the same role but can prove insufficient when dealing with a single opening. Common sense tells us that if you have an outstanding offer with one candidate, it's unlikely you'll extend an offer to a second candidate before hearing back from the first (hence the progression of the 2nd candidate is correlated to the 1st).
To mitigate this issue, the ideal solution involves creating a comprehensive simulation of how the hiring process might unfold, given the current set of candidates. Running this simulation multiple times will reveal a spectrum of outcomes. We can then analyse the distribution of scenarios to infer what is most likely to happen. For this, we're employing Monte Carlo methods. If successful, we'll have a comprehensive model of your hiring process that you can use for planning scenarios and getting ahead of potential issues.
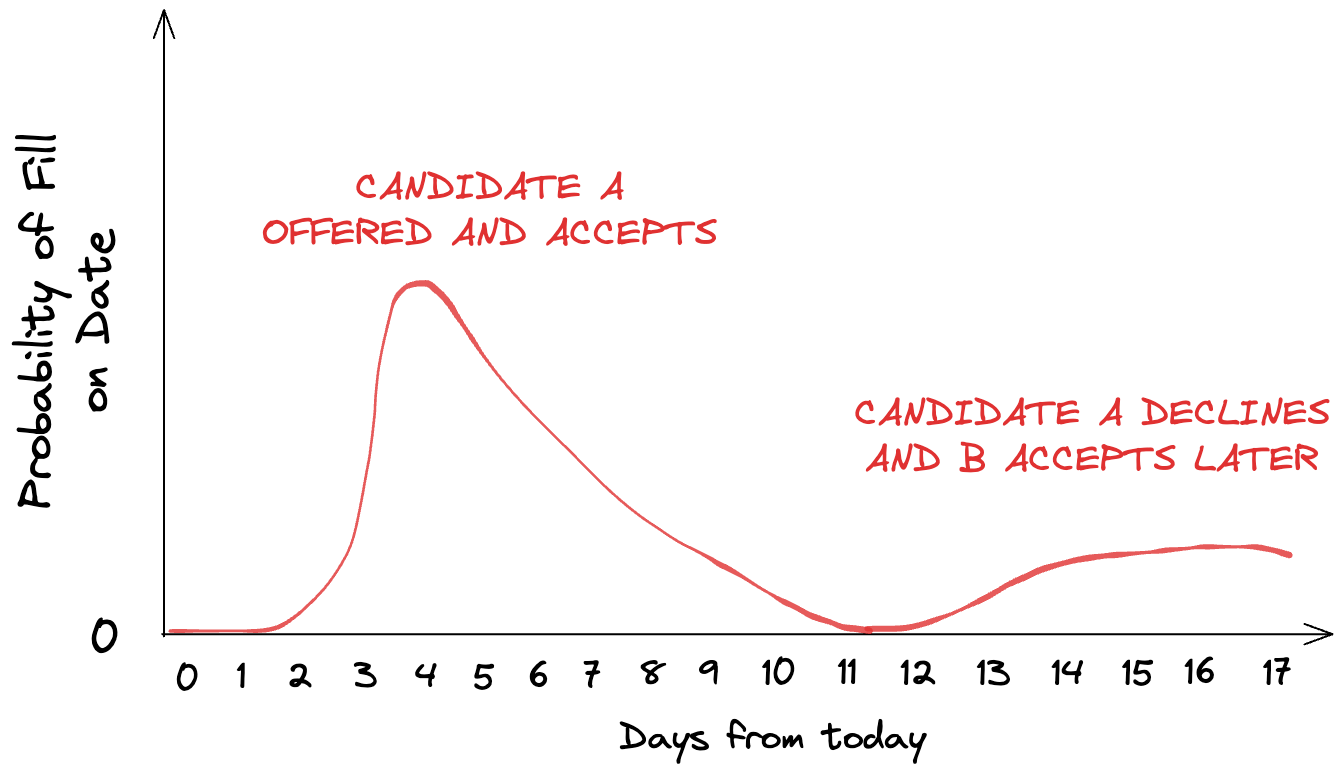
Thanks for reading!
We would love to hear your thoughts in the comments below. To stay updated with more from us, please consider subscribing to our mailing list. If you're interested in seeing Prologue firsthand, feel free to schedule a live demo with our co-founder, Patrick, here.